电子普票PDF自动解析:一篇给一线财务、运营的地气指南
|
admin 2026年1月8日 10:32
本文热度 363
2026年1月8日 10:32
本文热度 363
|
在不少做财务、运营、采购的一线同事眼中,电子普票PDF是一堆“不得不处理”的文件:要查金额、对税号、核往来、做台账,手工一张张打开、复制、粘贴,不仅枯燥,还容易出错。其实,这些重复劳动完全可以交给电脑来干。本文带你一步步看懂一段用 Python 写的“小工具”代码:自动遍历文件夹里的电子普票PDF,识别发票关键信息,并一键导出成Excel,尽量用通俗的方式,帮你看懂“它是怎么做的”,而不是只给你一堆代码。
这套代码主要分成三块: 配置区:把所有“规则”(正则、列名等)集中放在最上面。 发票处理逻辑:从PDF中提取文本和表格,用规则匹配出发票信息,再整理成Excel。 图形界面UI:做一个简单的窗口,让不懂代码的同事也能点几下就用。
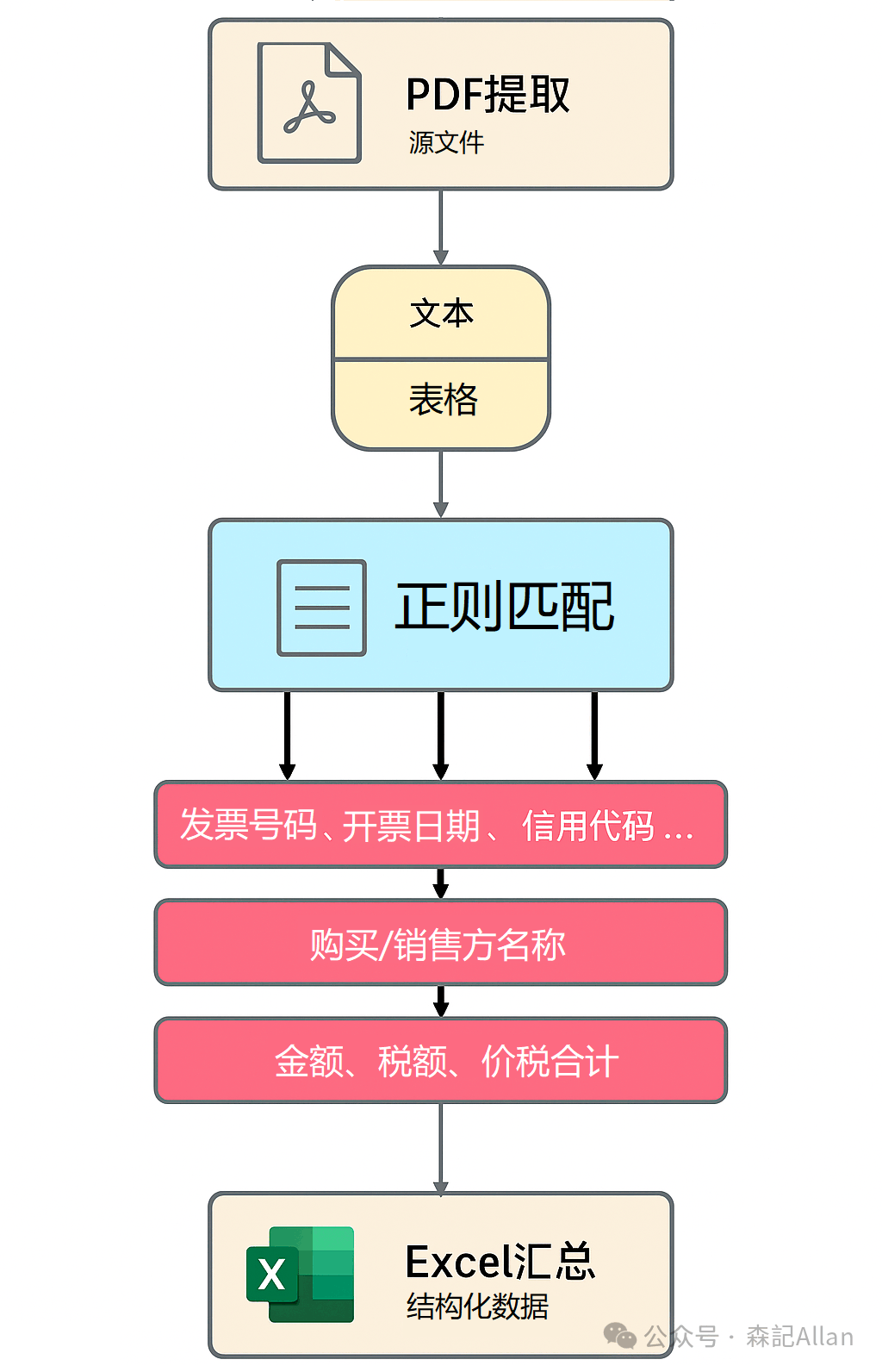
先上完整代码,然后我们一段一段拆开讲。
import pdfplumber, re, pandas as pd, os, tkinter as tkfrom tkinter import filedialog, messagebox
REGEX_PATTERNS = { "invoice_number": r"发票号码[::]?(\d{20})", "invoice_date": r"开票日期[::]?([^\n]*?日)", "tax_id": r"统一社会信用代码/纳税人识别号[::]?([0-9A-Z]+)", "buyer_name": r"名称[::]?\s*([^\n]+?)(?=销\s*名称[::])", "seller_name": r"销\s*名称[::]?\s*([^\n]+)", "amount_tax_table": r"¥\s*([0-9.]+)", "amount_tax_text": r"合\s*计.*?¥\s*([0-9.]+).*?¥\s*([0-9.]+)", "total": r"价税合计[^¥]*¥?\s*([0-9.,]+)"}
OUTPUT_COLUMNS = [ "文件名", "发票号码", "开票日期", "购买方名称", "购买方税号", "销售方名称", "销售方税号", "金额", "税额", "价税合计"]
DEFAULT_EXCEL_NAME = "发票汇总.xlsx"
def normalize_date(date_str): if date_str == "未识别": return date_str date_str = re.sub(r"\s+", "", date_str) for fmt in [r"(\d{4})年(\d{1,2})月(\d{1,2})日", r"(\d{4})[-/](\d{1,2})[-/](\d{1,2})日?"]: m = re.match(fmt, date_str) if m: return f"{m[1]}-{int(m[2]):02d}-{int(m[3]):02d}" return date_str
def extract_match(pattern, text, default="未识别", flags=0): m = re.search(pattern, text, flags) return m.group(1).strip() if m else default
class InvoiceProcessor: def __init__(self, folder, log_callback=None): self.folder, self.log_callback = folder, log_callback self.invoice_list = []
def log(self, msg): (self.log_callback or print)(msg)
def collect_pdfs(self): return [os.path.join(r,f) for r,_,fs in os.walk(self.folder) for f in fs if f.lower().endswith(".pdf")]
def extract_text_and_tables(self, path): try: with pdfplumber.open(path) as pdf: text = "\n".join(p.extract_text() or "" for p in pdf.pages) tables = [t for p in pdf.pages if (t:=p.extract_table())] return text, tables except Exception as e: self.log(f"无法读取 {path}: {e}") return None, None
def parse_invoice_info(self, text, tables): clean = re.sub(r"\s+", "", text) data = { "发票号码": extract_match(REGEX_PATTERNS["invoice_number"], clean), "开票日期": extract_match(REGEX_PATTERNS["invoice_date"], clean), "购买方税号": "未识别", "销售方税号": "未识别", "购买方名称": extract_match(REGEX_PATTERNS["buyer_name"], text, flags=re.S), "销售方名称": extract_match(REGEX_PATTERNS["seller_name"], text), "金额": "未识别", "税额": "未识别", "价税合计": extract_match(REGEX_PATTERNS["total"], text).replace(",", "") }
tax_ids = re.findall(REGEX_PATTERNS["tax_id"], clean) if tax_ids: data["购买方税号"] = tax_ids[0] if len(tax_ids) > 1: data["销售方税号"] = tax_ids[1]
for t in tables: for r in t: if any("合" in str(c) and "计" in str(c) for c in r if c): nums = re.findall(REGEX_PATTERNS["amount_tax_table"], " ".join(str(c) for c in r if c)) if nums: data["金额"], data["税额"] = nums[0], (nums[1] if len(nums)>1 else "未识别") break if "未识别" in (data["金额"], data["税额"]): m = re.search(REGEX_PATTERNS["amount_tax_text"], text.replace("\n","")) if m: data["金额"], data["税额"] = m[1], m[2]
return data
def process_all_invoices(self): files = self.collect_pdfs() for f in files: self.log(f"解析: {f}") text,tables = self.extract_text_and_tables(f) if text: info = self.parse_invoice_info(text,tables); info["文件名"]=os.path.basename(f) self.invoice_list.append(info)
def save_to_excel(self, filename=DEFAULT_EXCEL_NAME): if not self.invoice_list: return messagebox.showwarning("提示","无有效数据") df = pd.DataFrame(self.invoice_list) for col in ["购买方名称","销售方名称"]: df[col]=df[col].str.replace(r"\s+","",regex=True) df["开票日期"]=df["开票日期"].apply(normalize_date) df=df.sort_values("开票日期")[OUTPUT_COLUMNS] path=os.path.join(os.path.expanduser("~"),"Desktop",filename) df.to_excel(path,sheet_name="总表",index=False,engine="openpyxl")
class InvoiceUI: def __init__(self, root): root.title("发票处理工具"); root.geometry("390x150+590+350") tk.Label(root,text="选择文件夹:").grid(row=0,column=0,padx=10,pady=10,sticky="w") self.entry=tk.Entry(root,width=39); self.entry.grid(row=0,column=1,padx=10,pady=10,sticky="we") tk.Button(root,text="浏览",command=self.browse,width=12).grid(row=0,column=2,padx=10,pady=10) tk.Button(root,text="导出发票汇总",command=self.export,width=12).grid(row=1,column=2,padx=10,pady=10,sticky="w") root.grid_columnconfigure(1,weight=1)
def browse(self): if (f:=filedialog.askdirectory()): self.entry.delete(0,tk.END); self.entry.insert(0,f)
def export(self): folder=self.entry.get().strip() if not folder or not os.path.exists(folder): return messagebox.showerror("错误","请选择有效文件夹") p=InvoiceProcessor(folder); p.process_all_invoices(); p.save_to_excel(); messagebox.showinfo("完成","发票解析并导出完成!")
if __name__=="__main__": root=tk.Tk(); InvoiceUI(root); root.mainloop()
REGEX_PATTERNS = { "invoice_number": r"发票号码[::]?(\d{20})", "invoice_date": r"开票日期[::]?([^\n]*?日)", "tax_id": r"统一社会信用代码/纳税人识别号[::]?([0-9A-Z]+)", "buyer_name": r"名称[::]?\s*([^\n]+?)(?=销\s*名称[::])", "seller_name": r"销\s*名称[::]?\s*([^\n]+)", "amount_tax_table": r"¥\s*([0-9.]+)", "amount_tax_text": r"合\s*计.*?¥\s*([0-9.]+).*?¥\s*([0-9.]+)", "total": r"价税合计[^¥]*¥?\s*([0-9.,]+)"}
invoice_number:匹配“发票号码: 20位数字”,保证不会误抓其他数字。 invoice_date:匹配“开票日期”后面,一直到“日”为止,适配“2025年12月3日”这种格式。 tax_id:统一社会信用代码/纳税人识别号(企业税号)通常是大写字母+数字,用 [0-9A-Z]+。 buyer_name / seller_name:通过“名称”“销名称”两个标签来区分购买方、销售方,用前瞻 (?=销\s*名称[::]) 卡住分界。 amount_tax_table / amount_tax_text:分别用于处理“表格里的合计行”和“纯文本里的合计”。 total:价税合计金额,兼容“¥1,234.56”这种带逗号格式
| | | |
|---|
| | | 发票号码: 12345678901234567890 | | | | 开票日期: 2025年12月3日 | | 统一社会信用代码/纳税人识别号[::]?([0-9A-Z]+) | | 统一社会信用代码/纳税人识别号: 91320106MA1X123456 | | 名称[::]?\s*([^\n]+?)(?=销\s*名称[::]) | | 名称: 上海某某公司 销名称: 北京某某公司 | | | | 销名称: 北京某某公司 | | | | 合计 ¥1234.56 ¥246.91 | | 合\s*计.*?¥\s*([0-9.]+).*?¥\s*([0-9.]+) | | 合计: ¥1234.56 ¥246.91 | | | | 价税合计(小写): ¥1,481.47 |
OUTPUT_COLUMNS = [ "文件名", "发票号码", "开票日期", "购买方名称", "购买方税号", "销售方名称", "销售方税号", "金额", "税额", "价税合计"]DEFAULT_EXCEL_NAME = "发票汇总.xlsx"
def normalize_date(date_str): if date_str == "未识别": return date_str date_str = re.sub(r"\s+", "", date_str) for fmt in [r"(\d{4})年(\d{1,2})月(\d{1,2})日", r"(\d{4})[-/](\d{1,2})[-/](\d{1,2})日?"]: m = re.match(fmt, date_str) if m: return f"{m[1]}-{int(m[2]):02d}-{int(m[3]):02d}" return date_str
def extract_match(pattern, text, default="未识别", flags=0): m = re.search(pattern, text, flags) return m.group(1).strip() if m else default
四、InvoiceProcessor:发票处理的“发动机” 1. 初始化与日志
class InvoiceProcessor: def __init__(self, folder, log_callback=None): self.folder, self.log_callback = folder, log_callback self.invoice_list = []
def log(self, msg): (self.log_callback or print)(msg)
2. 收集PDF文件
def collect_pdfs(self): return [os.path.join(r,f) for r,_,fs in os.walk(self.folder) for f in fs if f.lower().endswith(".pdf")]
3. 从PDF中提取文本和表格
def extract_text_and_tables(self, path): try: with pdfplumber.open(path) as pdf: text = "\n".join(p.extract_text() or "" for p in pdf.pages) tables = [t for p in pdf.pages if (t:=p.extract_table())] return text, tables except Exception as e: self.log(f"无法读取 {path}: {e}") return None, None
def parse_invoice_info(self, text, tables): clean = re.sub(r"\s+", "", text) data = { "发票号码": extract_match(REGEX_PATTERNS["invoice_number"], clean), "开票日期": extract_match(REGEX_PATTERNS["invoice_date"], clean), "购买方税号": "未识别", "销售方税号": "未识别", "购买方名称": extract_match(REGEX_PATTERNS["buyer_name"], text, flags=re.S), "销售方名称": extract_match(REGEX_PATTERNS["seller_name"], text), "金额": "未识别", "税额": "未识别", "价税合计": extract_match(REGEX_PATTERNS["total"], text).replace(",", "") }
tax_ids = re.findall(REGEX_PATTERNS["tax_id"], clean)if tax_ids: data["购买方税号"] = tax_ids[0] if len(tax_ids) > 1: data["销售方税号"] = tax_ids[1]
金额/税额:先表格,后文本
for t in tables: for r in t: if any("合" in str(c) and "计" in str(c) for c in r if c): nums = re.findall(REGEX_PATTERNS["amount_tax_table"], " ".join(str(c) for c in r if c)) if nums: data["金额"], data["税额"] = nums[0], (nums[1] if len(nums)>1 else "未识别") breakif "未识别" in (data["金额"], data["税额"]): m = re.search(REGEX_PATTERNS["amount_tax_text"], text.replace("\n","")) if m: data["金额"], data["税额"] = m[1], m[2]
第一步:在表格中找含“合”“计”的那一行,通常就是合计行。 第二步:从这一行里用 ¥\s*([0-9.]+) 抓金额数字。 兜底:如果表格方式没抓到,再从纯文本里用“合计 … ¥金额 ¥税额”的规则匹配。
这样做的好处是:尽量利用结构化的表格信息,不行再靠文本兜底,综合识别率会高很多。
六、批量处理与导出Excel
1. 批量处理所有发票
def process_all_invoices(self): files = self.collect_pdfs() for f in files: self.log(f"解析: {f}") text,tables = self.extract_text_and_tables(f) if text: info = self.parse_invoice_info(text,tables); info["文件名"]=os.path.basename(f) self.invoice_list.append(info)
2. 清洗和导出


def save_to_excel(self, filename=DEFAULT_EXCEL_NAME): if not self.invoice_list: return messagebox.showwarning("提示","无有效数据") df = pd.DataFrame(self.invoice_list) for col in ["购买方名称","销售方名称"]: df[col]=df[col].str.replace(r"\s+","",regex=True) df["开票日期"]=df["开票日期"].apply(normalize_date) df=df.sort_values("开票日期")[OUTPUT_COLUMNS] path=os.path.join(os.path.expanduser("~"),"Desktop",filename) df.to_excel(path,sheet_name="总表",index=False,engine="openpyxl")
七、Tkinter界面:让同事点两下就能用
class InvoiceUI: def __init__(self, root): root.title("发票处理工具"); root.geometry("390x150+590+350") tk.Label(root,text="选择文件夹:").grid(row=0,column=0,padx=10,pady=10,sticky="w") self.entry=tk.Entry(root,width=39); self.entry.grid(row=0,column=1,padx=10,pady=10,sticky="we") tk.Button(root,text="浏览",command=self.browse,width=12).grid(row=0,column=2,padx=10,pady=10) tk.Button(root,text="导出发票汇总",command=self.export,width=12).grid(row=1,column=2,padx=10,pady=10,sticky="w") root.grid_columnconfigure(1,weight=1)
一个窗口,两行控件: 第一行:提示文字 + 输入框 + “浏览”按钮。 第二行:“导出发票汇总”按钮。
界面小而简单,适合日常用。
def browse(self): if (f:=filedialog.askdirectory()): self.entry.delete(0,tk.END); self.entry.insert(0,f)
def export(self): folder=self.entry.get().strip() if not folder or not os.path.exists(folder): return messagebox.showerror("错误","请选择有效文件夹") p=InvoiceProcessor(folder); p.process_all_invoices(); p.save_to_excel(); messagebox.showinfo("完成","发票解析并导出完成!")
浏览:弹出系统选文件夹窗口,将路径写入输入框。 导出:
if __name__=="__main__": root=tk.Tk(); InvoiceUI(root); root.mainloop()
- 这几行就是程序入口:启动 Tkinter 窗口,进入事件循环,等待用户操作。
发票版式变动:不同地区、不同开票系统可能在字段标签上有细微差异。建议收到失败样例时,把PDF内容抽取出来,在 REGEX_PATTERNS 增加或调整对应模式。 金额格式差异:有的会写成“¥ 1,234.56”或“RMB 1234.56”等,需要在 amount_tax_table 与 total 里加入更多容错匹配。 批量目录结构:供应商按月份分文件夹很常见,当前遍历已支持多层目录,但建议保持命名规范,避免把与发票无关的PDF混在一起。 日志落地:若放到服务器跑批,建议把 log_callback 指向文件写入函数,记录每个文件的解析结果与异常,方便审计与回溯。
阅读原文:https://mp.weixin.qq.com/s/1sg5Z3VaM7QDq1Eu5Wur4Q
该文章在 2026/1/8 10:50:58 编辑过
|
|







 400 186 1886
400 186 1886

