我不是很理解,为什么越来越多的项目打着高性能的旗号,迷信般的使用响应式编程框架,然后把代码搞的乱七八糟。响应式编程真的那么香么?还是“天下苦响应式编程久已”,在迫害我们的祖国花朵?在我看来,响应式编程至少犯了三宗罪:1. 易造成复杂;2. 调试困难;3. 性能迷雾。 鉴于此,我希望开发同学们在选择编程范式的时候,能擦亮自己的眼睛,选一个真正适合自己和团队的编程范式。
罪一、易造成复杂
响应式编程的代码通常比传统的命令式编程更复杂。它本质上是回调的封装,需要将一步一步的操作转换为一个一个的回调。因为底层采用的是观察者模式,需要我们把所有的业务操作都注册到Publisher里面,然后通过通知的模式去接收数据流动。为了发挥异步的效用,这根链条不能断,这就导致开发人员很容易写出有很多的点、点、点、点….可读性差、易出错的代码。如下所示,这是一段真实的项目代码示例:
private Mono<HyperClusterSwitch> ensureSwitchConfigured(String parentJobId, HyperClusterPort port) {
String switchIp = Optional.ofNullable(port.getLocation()).map(HyperClusterPort.Location::getSwitchIp)
.orElse(null);
Assert.hasText(switchIp, String.format("switchIp of port %s is blank", port.getId()));
return Mono.fromCallable(() -> {
HyperClusterSubnet subnet = subnetRepository.select(port.getHyperClusterSubnetId());
if (Objects.isNull(subnet)) {
String message = String.format("get subnet %s from redis failed", port.getHyperClusterSubnetId());
log.error(message);
throw new XlinkException(message);
}
return subnet;
}).retryWhen(Retry.backoff(3, Duration.ofSeconds(1))) // 并发优化
.doOnError(e -> log.error("XLINK.ALARM: get subnet {} from redis failed",
port.getHyperClusterSubnetId(), e))
.flatMap(subnet -> Mono
.fromCallable(() -> switchInfoRepository.select(port.getHyperClusterSubnetId(), switchIp))
.switchIfEmpty(Mono.fromCallable(() -> {
// switch加锁
String switchIpLock = String.format("xlink:hyper_cluster_switch:%s", switchIp);
redisLock.lock(switchIpLock, port.getId());
HyperClusterSwitch switchInfo = new HyperClusterSwitch();
switchInfo.setSwitchIp(switchIp);
switchInfo.setSwitchType(port.getLocation().getSwitchType());
// 为新关联的tor交换机分配vlan
Integer vlanId = allocateVlan(switchInfo);
switchInfo.setVlanId(vlanId);
// 将分配的vlan写入redis
switchInfoRepository.update(port.getHyperClusterSubnetId(), switchInfo);
// 释放switch锁
redisLock.unlock(switchIpLock, port.getId());
return switchInfo;
}).flatMap(switchInfo -> {
// 上报vlan分配结果到manager, 下发交换机本地vlan配置
return reportVlanToManager(port.getHyperClusterSubnetId(), switchInfo)
.then(sendSwitchAclConfigMsg(parentJobId, Constant.CREATE, switchInfo, subnet))
.then(sendSwitchVlanifConfigMsg(parentJobId, Constant.CREATE, switchInfo, subnet))
.thenReturn(switchInfo);
})).retryWhen(Retry.fixedDelay(3, Duration.ofSeconds(1))
.filter(ex -> ex instanceof XlinkException.LockError)));
}
说实话,这还不算糟糕的,比这个更长、更烂的Reactive代码比比皆是。可以说,但凡采用Reactive编程的项目,基本就是这样的调调。WTF!究其背后原因,我想这可能是因为响应式编程鼓励函数式编程,导致很多应该被对象封装的逻辑得不到封装和业务显性化的表达。从而导致长面条代码,可读性可理解性差。另外,因为是链式调用,多级回调之间的变量共享和传递也是隐式的,不直观。对于多个变量的传递只能用tuple之类的完全没有业务语义的对象。这样的代码从头贯穿到尾,一环套一环,就像一口气要唱完一首歌,给人透不过来气的感觉!再加上Reactive自身有非常多的操作符,其认知成本高和学习曲线长,导致很多同学很难精通,能把逻辑跑通就谢天谢地了,什么clean code、可读性、面向对象设计统统要给“这玩意”让路。
就我个人而言,所有导致代码可读性、可理解性、可维护性下降的行为都是大罪! 我最不能容忍的也正是响应式编程的这一罪状。有一说一,我并不排斥函数式,只是要分场景,比如大数据场景下的流式数据处理就非常合适用Reactive风格的函数式编程范式。我反对的是不分青红皂白的认为这个技术NB(NB是因为我写的代码别人看不懂?),滥用响应式编程污染我们的代码库。对于大部分的业务代码而言,用简单直观的方式,显性化的表达业务语义,让他人能看懂易理解,才是程序员最大的“善”。
罪二、调试困难
在响应式编程中,回调的堆栈里无法看到是谁放置了这个回调。这导致在排查问题时变得非常麻烦,因为无法准确追踪回调的调用关系。传统的堆栈,不管是调试时打的断点,还是日志中的异常栈,都是能看到哪个函数出错了,并向上逐级回溯调用方。但是响应式编程,在这个callback的堆栈里面是看不到谁放置了这个callback。
比如下面的代码:
return Mono
.fromSupplier(() -> SingleResponse.of(String.valueOf(current)))
.doOnNext(e -> log.info("before delay: " + new Date()))
.delayElement(Duration.ofSeconds(2)) //模拟业务停顿三秒
.doOnNext(e -> log.info("after delay: " + new Date())) // 断点处
.doOnNext(e -> {throw new RuntimeException("test");}); // 抛出异常处
如果我在“after delay”上面打上断点,你将看到下面所示的stack,我根本看不到我的前序步骤是什么,只能看到一大堆“无意义”的框架调用链。这种调用上下文的丢失对我们troubleshooting造成了极大的困难。
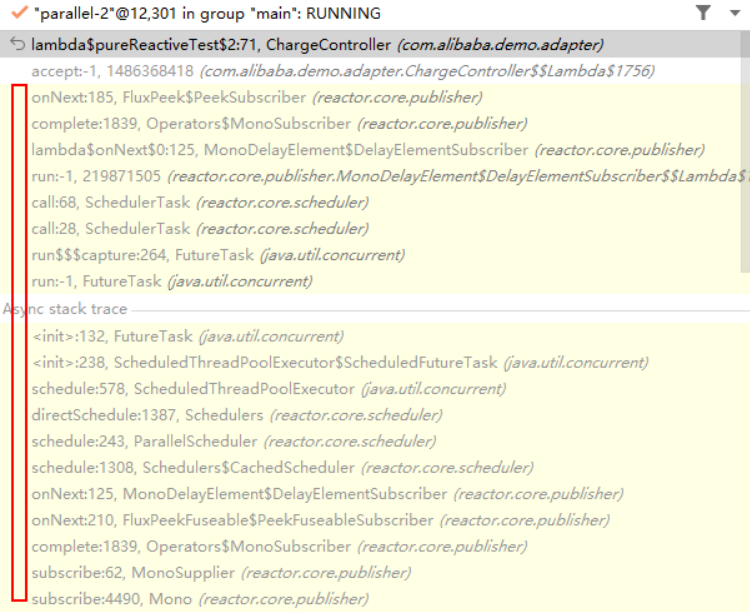
同样,对于上面代码中抛出的Exception,其异常堆栈是这样的,完全看不到我从哪里来,WTF!
java.lang.RuntimeException: test
at com.huawei.demo.adapter.ChargeController.lambda$pureReactiveTest$3(ChargeController.java:72)
at reactor.core.publisher.FluxPeek$PeekSubscriber.onNext(FluxPeek.java:185)
at reactor.core.publisher.FluxPeek$PeekSubscriber.onNext(FluxPeek.java:200)
at reactor.core.publisher.Operators$MonoSubscriber.complete(Operators.java:1839)
at reactor.core.publisher.MonoDelayElement$DelayElementSubscriber.lambda$onNext$0(MonoDelayElement.java:125)
at reactor.core.scheduler.SchedulerTask.call(SchedulerTask.java:68)
at reactor.core.scheduler.SchedulerTask.call(SchedulerTask.java:28)
at java.base/java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:264)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java)
at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
这种丢失调用方上下文的行为,是响应式编程的第二宗罪!
罪三、性能迷雾
使用响应式编程同学的最大理由就是性能提升。关于这一点,我自己亲自做了性能测试,事实证明想用好Reactive达到性能提升的目的,也并非易事,需要我们对其底层线程模型有非常深刻的理解,否则性能不仅不会提升还可能恶化。测试的硬件环境不重要,因为主要是对比。软件是这样的,Web服务器是Tomcat 9.0.82。压测工具是用JMeter发起1000个并发,每隔1秒发送一次,总共发送5次。我总共测试了4种情况:
1)情况一,使用普通的Spring MVC
实验代码如下:
@GetMapping("pressureTest")
public Response pressureTest() {
long start = System.currentTimeMillis();
log.info("pressureTest : " + start);
sleep("normalPressureTest", 2000); //模拟业务停顿2秒
long end = System.currentTimeMillis();
log.info("Pressure test, use time : " + (end - start));
return SingleResponse.of(String.valueOf(start));
}
我们用线程sleep 2秒来模拟业务处理时间,其测试结果如下。因为Tomcat的默认最大线程数是200,当压测开始时,200个线程会被全部启动。因为SpringMVC是thread-per-request模式,所以其处理的极限也就是100/S(因为业务处理需要2s,只有200个线程,所以每秒能处理的最大并发是200/2,也就是100),实测的结果是97/sec,可以理解。平均响应时间是10S怎么理解呢?这是因为服务器虽然同时收到了1000个request,但只有100/sec的处理能力,剩下的都得在缓存里排队,那么最后排到的那一波,可不就要10s才能返回么。如果并发量再大,超过Tomcat默认最多接收10000个connection的上线,缓存里放不下了,request就会直接被丢掉,或者等待时间过长,导致response time太长,发生TimeOut错误。

这里我们如果要做性能优化的话,最简单的方式就是加大线程数,比如我们可以在application.yml中调整最大线程数到400
server:
port: 8080
tomcat:
threads:
max: 400
按照我们上面的计算逻辑,同样是sleep 2秒,400个线程的极限值应该是200,实测结果是178/sec,也差不多

2)情况二,使用Spring WebFlux的reactive
接下来,我们把普通的MVC,改成WebFlux,看看情况怎么样,测试代码如下:
@GetMapping("reactiveThenTest")
public Mono<Response> reactiveThenTest() {
return Mono.fromCallable(() -> step1())
.doOnNext(i -> {
step2();
})
.doOnNext(i -> {
step3();
})
.thenReturn(Response.buildSuccess());
}
private Mono step1() {
sleep("step1", 600);
return Mono.empty();
}
private Mono step2() {
sleep("step2", 600);
return Mono.empty();
}
private Mono step3() {
sleep("step3", 800);
return Mono.empty();
}
我们把2s拆成3个step,分别让线程sleep 600ms、600ms和800ms,加起来也是2S。你们觉得吞吐率会怎样?实测结果如下:

同样是400个线程的配置,和SpringMVC的并发量基本是一样的。这是因为我们是直接在exec线程上使用了sleep,而Mono的操作又是同步顺序操作的,所以其效果是和SpringMVC一样的。这就是我说的,如果你不了解WebFlux的底层线程模型,用了Reactive也不一定就能提升性能,甚至还可能导致性能恶化,后面会提到。3)情况三,正确的使用异步处理能力
上面之所以性能没有提升,是因为我们的sleep操作block了exec线程,导致异步能力不能发挥,正确的delay方式应该是这样:
@GetMapping("pureReactivePressureTest")
public Mono<SingleResponse<String>> pureReactiveTest() {
Date current = new Date();
log.info("pureReactiveTest : " + current);
return Mono
.fromSupplier(() -> SingleResponse.of(String.valueOf(current)))
.doOnNext(e -> log.info("before delay: " + new Date())) // delay之前,在exec线程执行
.delayElement(Duration.ofSeconds(2)) //模拟业务停顿二秒
.doOnNext(e -> log.info("after delay: " + new Date())); // delay之后,在parallel线程执行
}
为什么说这才是正确的方式呢?我们先来看一下压测的结果,可以看到通过这种方式,我们的QPS达到了452/sec,平均Response Time是2S,性能翻倍了,这个收益还是很可观的。但是,前提是我们要用对。

之所以能达到这样的效果,是因为通过delayElement我们把延迟操作异步化,Reactor的delay实现是有专门的parallel线程来负责,然后等到delay时间到了以后,再通过事件机制callback,这样就不会阻塞exec线程的执行,相当于有400个exec线程一直在接客。关于这一点,我们可以通过如下的日志得到证实:
“before delay”是在exec线程中执行
16:14:57 INFO [http-nio-8080-exec-493] c.a.demo.adapter.ChargeController: before delay: Sat May 11 16:14:57 CST 2024
“after delay”是在parallel线程中执行
16:14:57 INFO [parallel-4] c.a.demo.adapter.ChargeController: after delay: Sat May 11 16:14:57 CST 2024
4)情况四,手动并行化
最后,我们来看一个可怕的情况。响应式编程本身是concurrency-agnostic的,其并发模型是开发人员自己控制的。因此我们可以手动设置parallel模式,以期达到并行处理的目的,我们不妨用一个Flux来试一试,其代码如下
@GetMapping("reactivePressureTest")
public Mono<Response> reactivePressureTest() {
log.info("Start reactivePressureTest");
return Flux.range(1, 3)
.parallel()
.runOn(Schedulers.parallel())
.doOnNext(i -> {
execute(i);
})
.then()
.thenReturn(Response.buildSuccess());
}
private Mono execute(int i) {
int sleepTime = 600;
if (i == 3) sleepTime = 800;
sleep("parallelStep" + i, sleepTime);
return Mono.empty();
}
上面代码的意图是说通过增加parallel线程,让execute函数可以并行被执行,当我们用Postman发送一个请求的时候,很好,因为并行,本来需要2s的操作,800ms就返回了,这正是我们想要的。然而,当我们启动和前面实验一样的1000个并发压测时,惨不忍睹的事情发生了:

吞吐量降低到只有37/sec,延迟达到了26s,因为超时造成96%的错误率。 这就是我说的,用不好可能导致性能恶化的情况。造成这种情况的原因是,系统的默认的parallel线程数等于cpu的核数,我电脑是8核的,所以这里有8个parallel线程,又因为我们手动block了parallel线程,导致瓶颈点积压到8个parallel线程身上。尽管在外围我们有NIO的无阻塞acceptor接收请求,分发给400个exec线程工作,但都被block在8个parallel线程这里了,相当于整个系统只有8个线程在工作,不慢才怪。






 400 186 1886
400 186 1886


