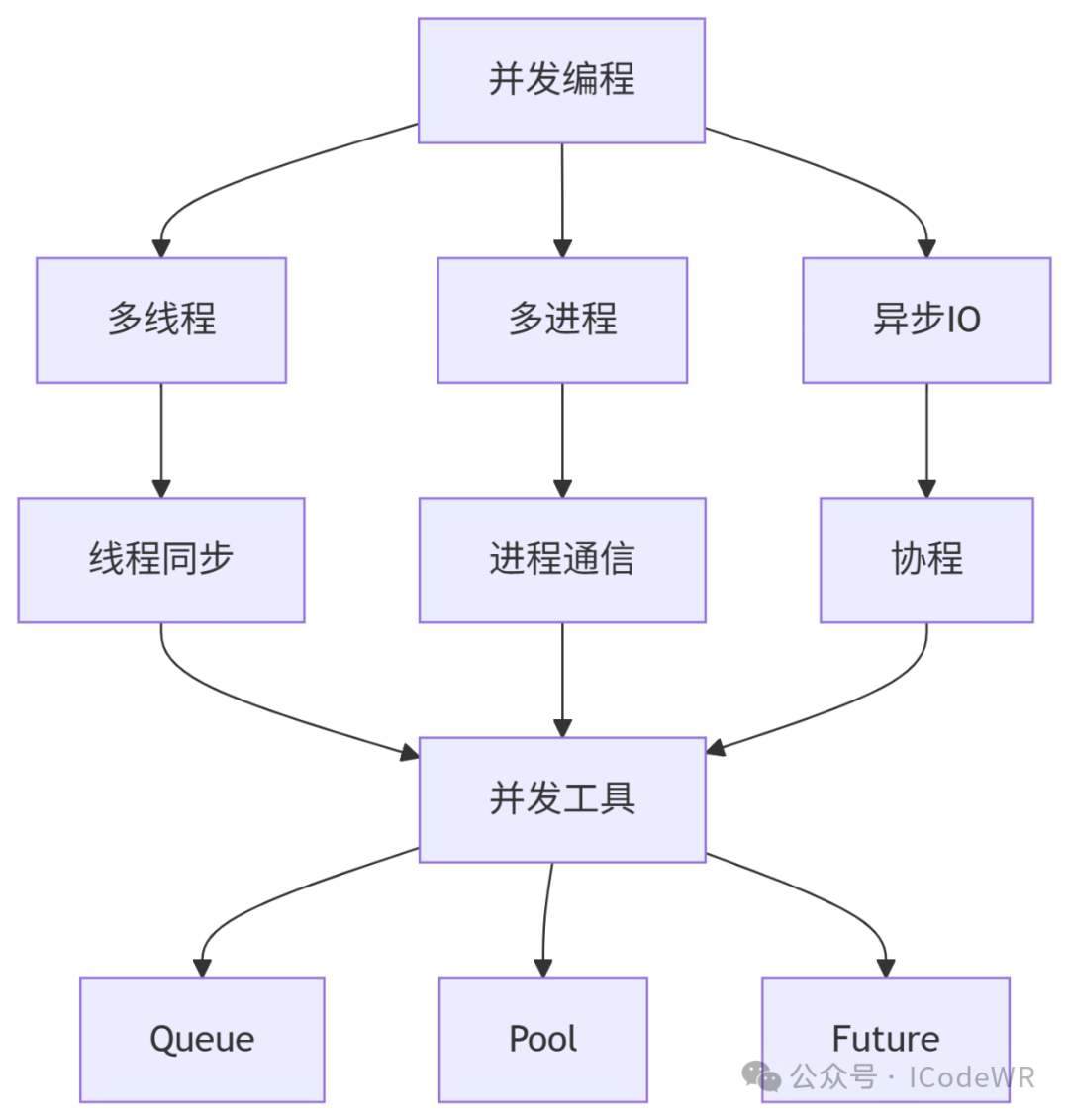
并发编程是现代软件开发中不可或缺的技能,Python提供了多种并发编程模型。本指南将系统性地介绍Python中的各种并发技术,包括多线程、多进程、协程以及相关工具库的使用。
1.1 并发与并行
并发(Concurrency):指系统能够处理多个任务的能力,这些任务在时间上重叠,但不一定同时执行。在单核CPU上,通过时间片轮转实现并发。
并行(Parallelism):指系统能够同时执行多个任务,需要多核CPU支持。
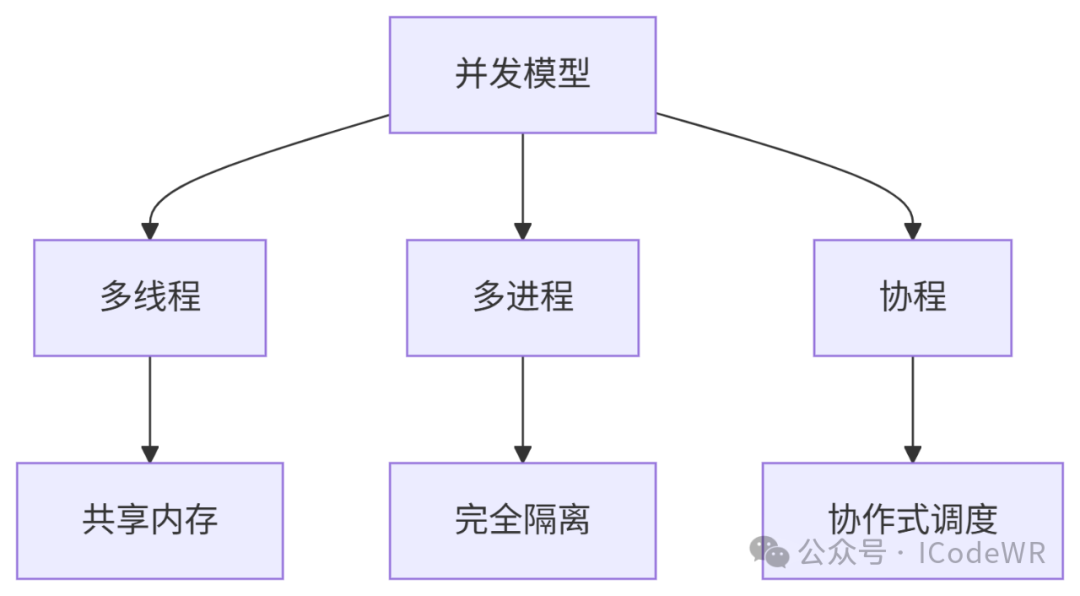
1.2 Python中的并发模型
Python提供了三种主要的并发编程模型:
- 多线程:适合I/O密集型任务
- 多进程:适合CPU密集型任务
- 协程(异步IO):适合高并发的I/O操作
1.3 GIL全局解释器锁
全局解释器锁(GIL) 是Python解释器中的一个机制,它确保任何时候只有一个线程执行Python字节码。这对并发编程有重要影响:
- 优点:简化了CPython实现,使对象模型(包括关键的内建类型如字典)隐式地避免了并发访问的竞争条件
- 缺点:限制了多线程在CPU密集型任务中的性能
GIL的影响:
- I/O操作(文件、网络)会释放GIL,因此I/O密集型任务仍可受益于多线程
2.1 threading模块基础
Python的threading模块提供了高级的线程接口。与低级的_thread模块相比,它提供了更多功能和更好的抽象。
创建线程的基本方法:
import threading
import time
defworker(num):
print(f"Worker {num} 开始执行")
time.sleep(1)
print(f"Worker {num} 执行完成")
# 创建线程
threads = []
for i inrange(3):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
关键点:
Threadtargetargsstart()join()
2.2 线程同步
当多个线程需要访问共享资源时,必须使用同步机制来避免竞态条件。
2.2.1 锁(Lock)
最基本的同步原语,一次只允许一个线程访问共享资源。
import threading
classCounter:
def__init__(self):
self.value = 0
self.lock = threading.Lock()
defincrement(self):
withself.lock: # 自动获取和释放锁
self.value += 1
counter = Counter()
defincrement_worker():
for _ inrange(100000):
counter.increment()
threads = [threading.Thread(target=increment_worker) for _ inrange(2)]
for t in threads:
t.start()
for t in threads:
t.join()
print(f"最终计数: {counter.value}") # 应为200000
锁的使用:
2.2.2 其他同步原语
- RLock(可重入锁):允许同一个线程多次获取锁
- Semaphore:限制同时访问资源的线程数量
- Event:线程间通信的简单方式
- Condition:复杂的线程通信机制
2.3 线程池
concurrent.futures.ThreadPoolExecutor提供了方便的线程池接口。
from concurrent.futures import ThreadPoolExecutor
import urllib.request
URLS = ['http://example.com', 'http://example.org']
defload_url(url, timeout=60):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
with ThreadPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
print(f"{url} 页面长度为 {len(data)}")
except Exception as e:
print(f"{url} 获取失败: {e}")
线程池的优点:
3.1 multiprocessing模块
multiprocessing模块提供了类似于threading模块的API,但使用进程而非线程。
from multiprocessing import Process
import os
deftask(name):
print(f"子进程 {name} (PID: {os.getpid()}) 执行中...")
result = sum(i*i for i inrange(1000000))
print(f"子进程 {name} 完成")
if __name__ == '__main__':
processes = []
for i inrange(4): # 4核CPU常用
p = Process(target=task, args=(i,))
processes.append(p)
p.start()
for p in processes:
p.join()
多进程特点:
3.2 进程间通信(IPC)
3.2.1 Queue
multiprocessing.Queue是进程安全的队列实现。
from multiprocessing import Process, Queue
defproducer(q):
for item in ['A', 'B', 'C']:
q.put(item)
print(f"生产: {item}")
defconsumer(q):
whileTrue:
item = q.get()
if item isNone: # 终止信号
break
print(f"消费: {item}")
if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer, args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
p1.join()
q.put(None) # 发送终止信号
p2.join()
3.2.2 Pipe
multiprocessing.Pipe提供了一对连接对象,用于双向通信。
from multiprocessing import Process, Pipe
def worker(conn):
conn.send("Hello from worker")
print("Worker received:", conn.recv())
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(child_conn,))
p.start()
print("Parent received:", parent_conn.recv())
parent_conn.send("Hello from parent")
p.join()
3.3 进程池
multiprocessing.Pool提供了进程池功能。
from multiprocessing import Pool
def cpu_intensive(n):
return sum(i * i for i in range(n))
if __name__ == '__main__':
with Pool(4) as pool: # 4个工作进程
results = pool.map(cpu_intensive, range(10000, 10010))
print(results)
进程池方法:
map(func, iterable):并行处理可迭代对象apply(func, args):同步执行函数apply_async(func, args):异步执行函数imap(func, iterable):惰性版本的map
4.1 协程基础
协程是轻量级的用户态线程,由事件循环调度。
import asyncio
asyncdeffetch_data(url):
print(f"开始获取 {url}")
await asyncio.sleep(2) # 模拟IO操作
print(f"完成获取 {url}")
returnf"{url} 的数据"
asyncdefmain():
task1 = asyncio.create_task(fetch_data("url1"))
task2 = asyncio.create_task(fetch_data("url2"))
results = await asyncio.gather(task1, task2)
print(results)
asyncio.run(main())
关键概念:
async def:定义协程函数await:挂起协程,等待结果asyncio.run():运行协程create_task():调度协程执行gather():并发运行多个协程
4.2 异步IO操作
使用aiohttp进行异步HTTP请求:
import aiohttp
import asyncio
asyncdeffetch_page(url):
asyncwith aiohttp.ClientSession() as session:
asyncwith session.get(url) as response:
returnawait response.text()
asyncdefmain():
urls = [
"http://example.com",
"http://example.org",
"http://example.net"
]
tasks = [fetch_page(url) for url in urls]
pages = await asyncio.gather(*tasks)
print(f"获取了 {len(pages)} 个页面")
asyncio.run(main())
异步编程要点:
- 使用专为asyncio设计的库(aiohttp, asyncpg等)
5.1 并发Web爬虫
import aiohttp
import asyncio
from urllib.parse import urljoin
from bs4 import BeautifulSoup
asyncdefcrawl(start_url, max_depth=2):
visited = set()
queue = [(start_url, 0)]
asyncwith aiohttp.ClientSession() as session:
while queue:
url, depth = queue.pop(0)
if url in visited or depth > max_depth:
continue
try:
print(f"抓取: {url}")
asyncwith session.get(url) as response:
html = await response.text()
visited.add(url)
if depth < max_depth:
soup = BeautifulSoup(html, 'html.parser')
for link in soup.find_all('a', href=True):
next_url = urljoin(url, link['href'])
if next_url notin visited:
queue.append((next_url, depth + 1))
except Exception as e:
print(f"抓取失败 {url}: {e}")
asyncio.run(crawl("http://example.com"))
5.2 实时数据处理管道
import threading
import queue
import random
import time
classDataPipeline:
def__init__(self):
self.raw_data_queue = queue.Queue()
self.processed_data = []
self.lock = threading.Lock()
defdata_source(self):
whileTrue:
data = random.randint(1, 100)
self.raw_data_queue.put(data)
time.sleep(0.1)
defdata_processor(self):
whileTrue:
data = self.raw_data_queue.get()
time.sleep(0.2)
result = data * 2
withself.lock:
self.processed_data.append(result)
print(f"处理数据: {data} -> {result} (队列大小: {self.raw_data_queue.qsize()})")
defstart(self):
threads = [
threading.Thread(target=self.data_source, daemon=True),
threading.Thread(target=self.data_processor, daemon=True),
threading.Thread(target=self.data_processor, daemon=True)
]
for t in threads:
t.start()
try:
whileTrue:
time.sleep(1)
withself.lock:
print(f"当前处理结果数: {len(self.processed_data)}")
except KeyboardInterrupt:
print("停止管道")
if __name__ == '__main__':
pipeline = DataPipeline()
pipeline.start()
任务类型分析:
资源管理:
错误处理:
性能优化:
调试技巧:
- 使用
threading.current_thread().name标识线程 - 使用
multiprocessing.current_process().name标识进程
死锁问题:
- 现象:程序挂起,无响应
- 解决:按固定顺序获取锁,使用带超时的锁
资源竞争:
- 现象:数据不一致或程序崩溃
- 解决:使用适当的同步原语保护共享资源
性能瓶颈:
- 现象:增加并发数但性能不提升
- 解决:分析系统资源使用情况,可能是I/O或外部服务限制
内存泄漏:
- 现象:内存使用持续增长
- 解决:确保资源正确释放,使用内存分析工具
协程阻塞:
- 现象:异步程序响应慢
- 解决:检查是否有同步阻塞调用,使用
loop.run_in_executor处理阻塞操作
分布式任务队列:
Actor模型:
高性能并发框架:
并行计算:
微服务与并发:
通过系统学习和实践这些并发编程技术,将能够构建高性能、高并发的Python应用程序。
阅读原文:原文链接
该文章在 2025/7/18 10:50:58 编辑过






 400 186 1886
400 186 1886