1.1 数据库类型对比
在Python数据库编程中,主要使用两种类型的数据库:
关系型数据库 (RDBMS):
- 遵循ACID原则(原子性、一致性、隔离性、持久性)
- 典型代表:MySQL、PostgreSQL、SQLite
NoSQL数据库:
- 典型代表:MongoDB(文档型)、Redis(键值对)
1.2 Python DB-API规范
Python的DB-API是数据库操作的标准化接口,核心组件包括:
connect()cursor()execute()fetchone()/fetchall()commit()/rollback()
注意事项:
2.1 基本CRUD操作
import sqlite3
# 创建连接(自动创建数据库文件)
conn = sqlite3.connect('example.db', check_same_thread=False)
cursor = conn.cursor()
# 创建表(IF NOT EXISTS避免重复创建)
cursor.execute('''CREATE TABLE IF NOT EXISTS users
(id INTEGER PRIMARY KEY, name TEXT, age INTEGER)''')
# 插入数据(使用参数化查询)
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Alice', 25))
# 查询数据
cursor.execute("SELECT * FROM users WHERE age > ?", (20,))
print(cursor.fetchall()) # 获取所有匹配记录
# 更新数据
cursor.execute("UPDATE users SET age = ? WHERE name = ?", (26, 'Alice'))
# 删除数据
cursor.execute("DELETE FROM users WHERE id = ?", (1,))
# 提交事务并关闭连接
conn.commit()
conn.close()
2.2 高级特性
# 使用上下文管理器自动处理连接
with sqlite3.connect('example.db') as conn:
conn.row_factory = sqlite3.Row # 字典式访问结果
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
for row in cursor:
print(f"{row['name']}, {row['age']}") # 列名访问
# 内存数据库(临时数据库)
mem_db = sqlite3.connect(':memory:')
实践建议:
3.1 PyMySQL操作MySQL
import pymysql
# 连接MySQL数据库
conn = pymysql.connect(
host='localhost',
user='root',
password='password',
database='test',
cursorclass=pymysql.cursors.DictCursor # 返回字典格式结果
)
try:
with conn.cursor() as cursor:
# 创建表
cursor.execute("""CREATE TABLE IF NOT EXISTS products (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price DECIMAL(10,2) NOT NULL)""")
# 插入数据
sql = "INSERT INTO products (name, price) VALUES (%s, %s)"
cursor.execute(sql, ('Laptop', 999.99))
# 查询数据
cursor.execute("SELECT * FROM products WHERE price > %s", (500,))
result = cursor.fetchone()
print(result)
# 提交事务
conn.commit()
finally:
conn.close() # 确保连接关闭
3.2 psycopg2操作PostgreSQL
import psycopg2
# 连接PostgreSQL
conn = psycopg2.connect(
host="localhost",
database="test",
user="postgres",
password="password"
)
# 使用上下文管理自动提交事务
with conn:
with conn.cursor() as cursor:
# 插入数据并返回生成的ID
cursor.execute("""
INSERT INTO orders (customer, total)
VALUES (%s, %s)
RETURNING id
""", ("John Doe", 150.75))
order_id = cursor.fetchone()[0]
print(f"新订单ID: {order_id}")
关键点:
- MySQL使用
%s作为占位符,PostgreSQL也使用%s - PostgreSQL支持
RETURNING子句获取插入后的数据
4. ORM框架:SQLAlchemy与Django ORM
4.1 SQLAlchemy核心操作
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.orm import declarative_base, relationship, sessionmaker
Base = declarative_base()
# 定义数据模型
classUser(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50))
email = Column(String(100), unique=True)
orders = relationship("Order", back_populates="user")
classOrder(Base):
__tablename__ = 'orders'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('users.id'))
total = Column(Integer)
user = relationship("User", back_populates="orders")
# 初始化数据库连接
engine = create_engine('sqlite:///mydatabase.db')
Base.metadata.create_all(engine)
# 创建会话
Session = sessionmaker(bind=engine)
session = Session()
# 添加新用户和订单
new_user = User(name="Alice", email="alice@example.com")
new_order = Order(total=100, user=new_user)
session.add(new_user)
session.add(new_order)
session.commit()
# 查询操作
user = session.query(User).filter_by(email="alice@example.com").first()
print(f"用户: {user.name}, 订单数: {len(user.orders)}")
session.close()
4.2 Django ORM查询
# models.py
from django.db import models
classProduct(models.Model):
name = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
category = models.ForeignKey('Category', on_delete=models.CASCADE)
created_at = models.DateTimeField(auto_now_add=True)
classCategory(models.Model):
name = models.CharField(max_length=50)
# 查询操作
from django.db.models import Q, F, Count
# 复杂查询
products = Product.objects.filter(
Q(price__lt=100) | Q(name__startswith="Premium"),
created_at__year=2023
).annotate(
discounted_price=F('price') * 0.9
).select_related('category')
# 聚合查询
from django.db.models import Avg, Sum
category_stats = Category.objects.annotate(
product_count=Count('product'),
avg_price=Avg('product__price')
).filter(product_count__gt=5)
ORM优势:
5.1 MongoDB文档操作
from pymongo import MongoClient
from datetime import datetime
# 连接MongoDB
client = MongoClient('mongodb://localhost:27017/')
db = client['ecommerce']
products = db['products']
# 插入文档
product_data = {
"name": "Wireless Headphones",
"price": 129.99,
"categories": ["Electronics", "Audio"],
"stock": 50,
"last_updated": datetime.utcnow()
}
result = products.insert_one(product_data)
print(f"插入文档ID: {result.inserted_id}")
# 查询文档
query = {"price": {"$lt": 150}, "categories": "Electronics"}
for product in products.find(query).sort("price", -1).limit(5):
print(product["name"], product["price"])
# 聚合管道
pipeline = [
{"$match": {"price": {"$gt": 100}}},
{"$group": {
"_id": "$category",
"avg_price": {"$avg": "$price"},
"count": {"$sum": 1}
}}
]
results = products.aggregate(pipeline)
5.2 Redis缓存与数据结构
import redis
# 连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 字符串操作
r.set('site:visits', 100, ex=3600) # 设置1小时过期
r.incr('site:visits') # 增加访问计数
# 哈希操作(存储对象)
r.hset('user:1000', mapping={
'name': 'Alice',
'email': 'alice@example.com',
'last_login': '2023-06-15'
})
# 集合操作(标签系统)
r.sadd('product:123:tags', 'electronics', 'wireless', 'audio')
# 有序集合(排行榜)
r.zadd('leaderboard', {'player1': 100, 'player2': 85, 'player3': 120})
top_players = r.zrevrange('leaderboard', 0, 2, withscores=True)
NoSQL适用场景举例:
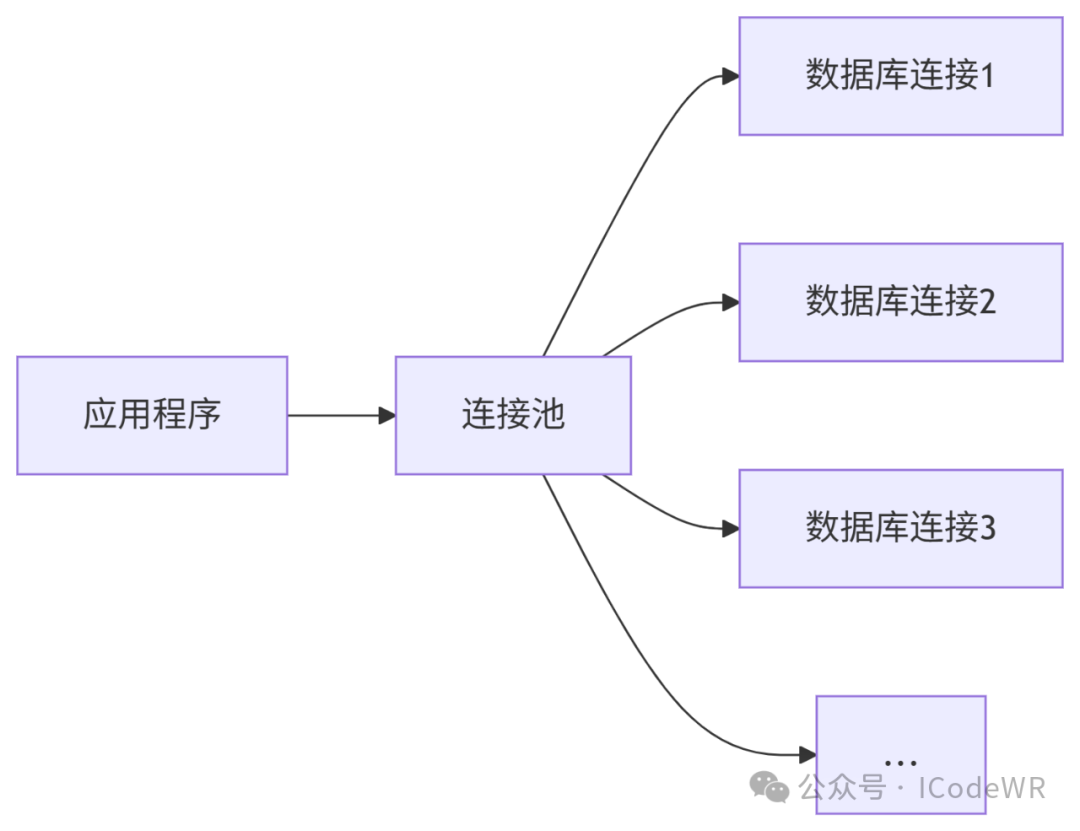
6.1 SQLAlchemy连接池实现
from sqlalchemy import create_engine
from sqlalchemy.pool import QueuePool
# 创建连接池
engine = create_engine(
'mysql+pymysql://user:password@localhost/dbname',
poolclass=QueuePool,
pool_size=10, # 常驻连接数
max_overflow=5, # 最大临时连接数
pool_timeout=30, # 获取连接超时时间(秒)
pool_recycle=3600 # 连接回收时间(秒)
)
# 使用连接
with engine.connect() as conn:
result = conn.execute("SELECT * FROM users")
for row in result:
print(row)
6.2 连接池实践
连接池大小设置:
连接回收策略:
- 设置合理的
pool_recycle值(通常小于数据库连接超时时间)
资源管理:
7.1 电商订单系统示例
# 使用SQLAlchemy实现电商核心模型
from sqlalchemy import Column, Integer, String, Float, ForeignKey, DateTime
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
import datetime
Base = declarative_base()
classUser(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
email = Column(String(100), unique=True)
orders = relationship("Order", back_populates="user")
classProduct(Base):
__tablename__ = 'products'
id = Column(Integer, primary_key=True)
name = Column(String(100), nullable=False)
price = Column(Float, nullable=False)
stock = Column(Integer, default=0)
classOrder(Base):
__tablename__ = 'orders'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('users.id'))
created_at = Column(DateTime, default=datetime.datetime.utcnow)
status = Column(String(20), default='pending')
user = relationship("User", back_populates="orders")
items = relationship("OrderItem", back_populates="order")
classOrderItem(Base):
__tablename__ = 'order_items'
id = Column(Integer, primary_key=True)
order_id = Column(Integer, ForeignKey('orders.id'))
product_id = Column(Integer, ForeignKey('products.id'))
quantity = Column(Integer, default=1)
price = Column(Float) # 下单时的价格快照
order = relationship("Order", back_populates="items")
product = relationship("Product")
# 使用示例
defcreate_order(user, products):
"""创建新订单"""
order = Order(user=user)
for product, quantity in products:
# 检查库存
if product.stock < quantity:
raise ValueError(f"{product.name}库存不足")
# 创建订单项
order.items.append(OrderItem(
product=product,
quantity=quantity,
price=product.price
))
# 减少库存
product.stock -= quantity
return order
7.2 数据库缓存策略示例
import sqlite3
import redis
import json
import time
classCachedDB:
"""带Redis缓存的数据库访问层"""
def__init__(self, db_path=':memory:', cache_expire=300):
self.redis = redis.Redis(host='localhost', port=6379, db=0)
self.db_conn = sqlite3.connect(db_path)
self.cache_expire = cache_expire # 缓存过期时间(秒)
self._init_db()
def_init_db(self):
"""初始化数据库表结构"""
cur = self.db_conn.cursor()
cur.execute('''CREATE TABLE IF NOT EXISTS articles (
id INTEGER PRIMARY KEY,
title TEXT NOT NULL,
content TEXT,
views INTEGER DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)''')
self.db_conn.commit()
defget_article(self, article_id):
"""获取文章(带缓存)"""
cache_key = f"article:{article_id}"
cached = self.redis.get(cache_key)
if cached:
# 缓存命中
article = json.loads(cached)
article['from_cache'] = True
return article
# 缓存未命中,查询数据库
cur = self.db_conn.cursor()
cur.execute("SELECT * FROM articles WHERE id=?", (article_id,))
row = cur.fetchone()
ifnot row:
returnNone
# 更新访问计数
cur.execute("UPDATE articles SET views = views + 1 WHERE id=?", (article_id,))
self.db_conn.commit()
# 构建文章对象
article = {
'id': row[0],
'title': row[1],
'content': row[2],
'views': row[3],
'created_at': row[4],
'from_cache': False
}
# 写入缓存
self.redis.setex(cache_key, self.cache_expire, json.dumps(article))
return article
defcreate_article(self, title, content):
"""创建新文章"""
cur = self.db_conn.cursor()
cur.execute("INSERT INTO articles (title, content) VALUES (?, ?)",
(title, content))
self.db_conn.commit()
article_id = cur.lastrowid
# 清除可能的缓存
self.redis.delete(f"article:{article_id}")
return article_id
defsearch_articles(self, keyword):
"""文章搜索(不使用缓存)"""
cur = self.db_conn.cursor()
cur.execute("SELECT id, title FROM articles WHERE title LIKE ? OR content LIKE ?",
(f'%{keyword}%', f'%{keyword}%'))
return [dict(id=row[0], title=row[1]) for row in cur.fetchall()]
安全第一:
性能优化:
代码可维护性:
错误处理:
测试与监控:
通过掌握这些知识和技巧,我们将能够构建高效、安全且可维护的Python数据库应用程序。
阅读原文:原文链接
该文章在 2025/7/18 10:53:58 编辑过






 400 186 1886
400 186 1886