python第三方库PyMuPDF:如何提取pdf中表格数据
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
背景:从PDF文件中提取表格都是一个老大难的问题。无论你使用的是PyPDF2还是其他什么第三方库,提取出来的表格都会变成纯文本,效果并不好。公司之前有很多的研报pdf解析,都是通过买的第三方服务来解析的,偶然间发现 python第三方库
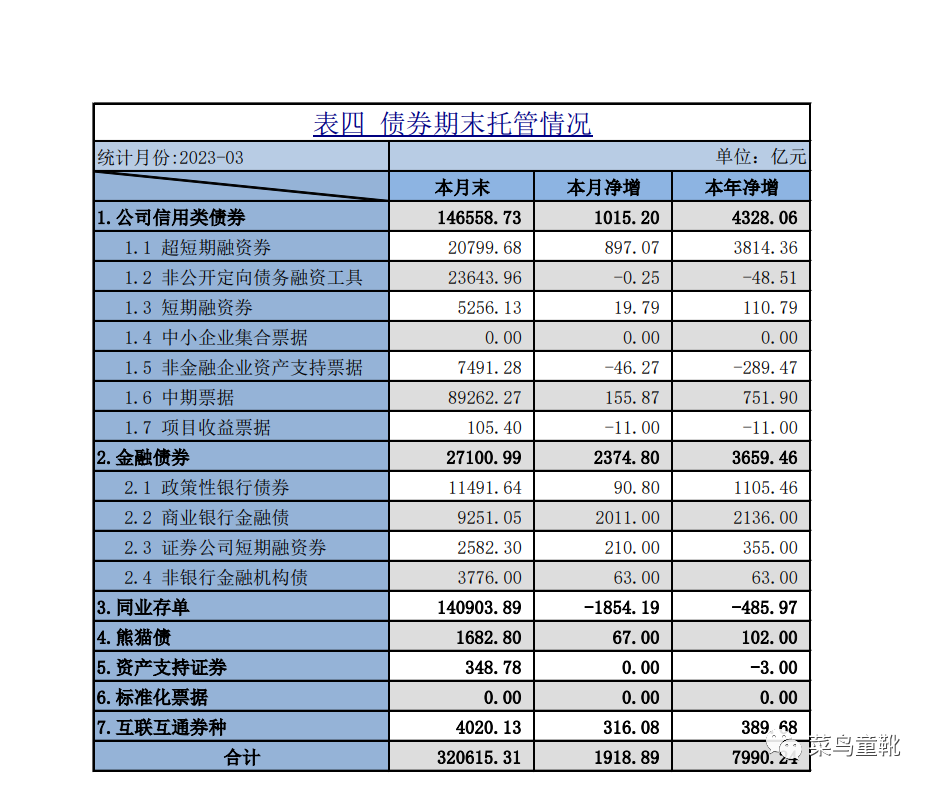
pip install pymupdf==1.23.0 pandas openpyxl首先我们从网址上海清算所_研究与统计 (shclearing.com.cn), https://www.shclearing.com.cn/sjtj/tjyb/ 下载债券期末托管的pdf,pdf中表格如下:
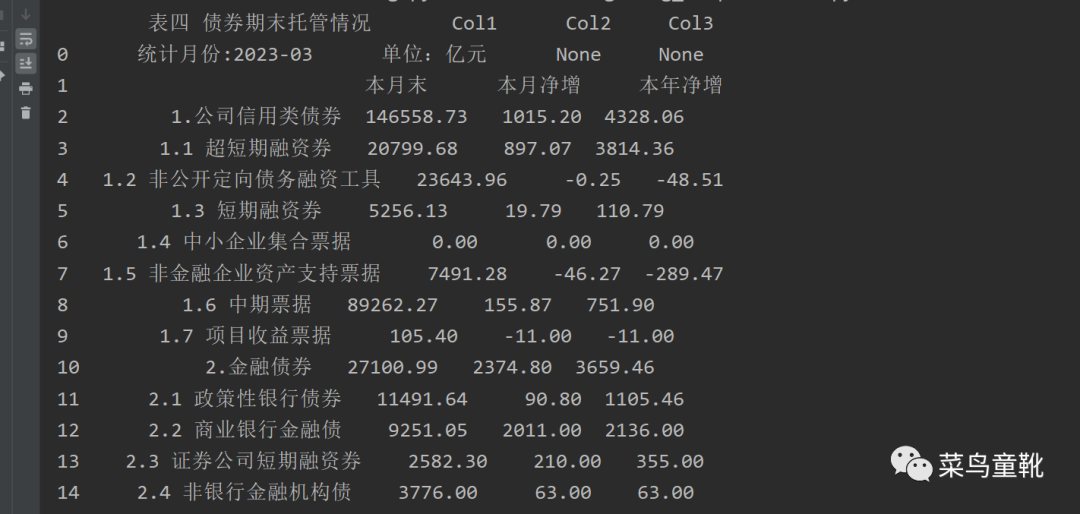
确定好解析文件后,让我们开始编写代码 import fitz root_path = "./表四 债券期末托管情况2023-07-31.pdf" doc = fitz.open(root_path) page = doc[0] # 下标从0开始,第五页对应4 tables = page.find_tables() df = tables[0].to_pandas() print(df) df.to_excel('table.xlsx', index=False)
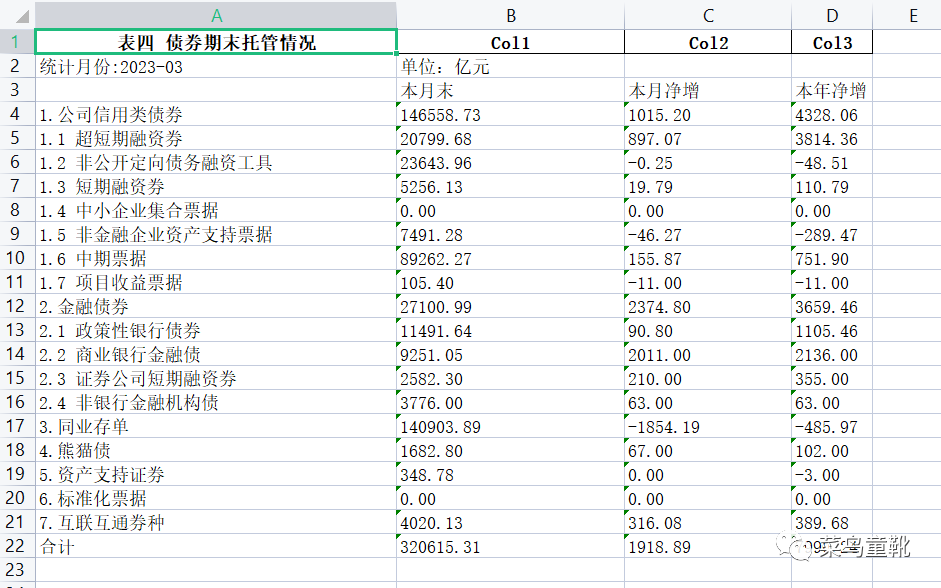
保存table.xlsx 效果如下
下面我们将解析过程中的df数据转换成json列表,截个图吧,公众号的代码粘贴太丑:
阅读原文:原文链接 该文章在 2025/8/28 16:33:05 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886