python提取pdf表格数据并保存到excel中
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
pdfplumber操作pdf文件 python开源库pdfplumber,可以较为方便地获取pdf的各种信息,包含pdf的基本信息(作者、创建时间、修改时间...)及表格、文本、图片等信息,基本可以满足较为简单的格式转换功能。 一、pdfplumber安装及导入 跟其他包一样,支持使用pip安装,安装命令:
安装成功后,可直接用import导入,导入命令:
二、pdfplumber基础使用 1、基础知识 (1)pdfplumber有2个基础类 PDF和Page,PDF用来处理整个文档,Page用来处理整个页面。
(2)pdfplumber读取pdf文件方式 pdfplumber.open(‘文件路径’),返回pdfplumber.PDF类的实例。 如果pdf有密码,加入password参数: pdfplumber.open(‘文件路径’,password=‘密码’) 2、获取pdf基础信息 读取pdf文件,并输出pdf文件的基础信息
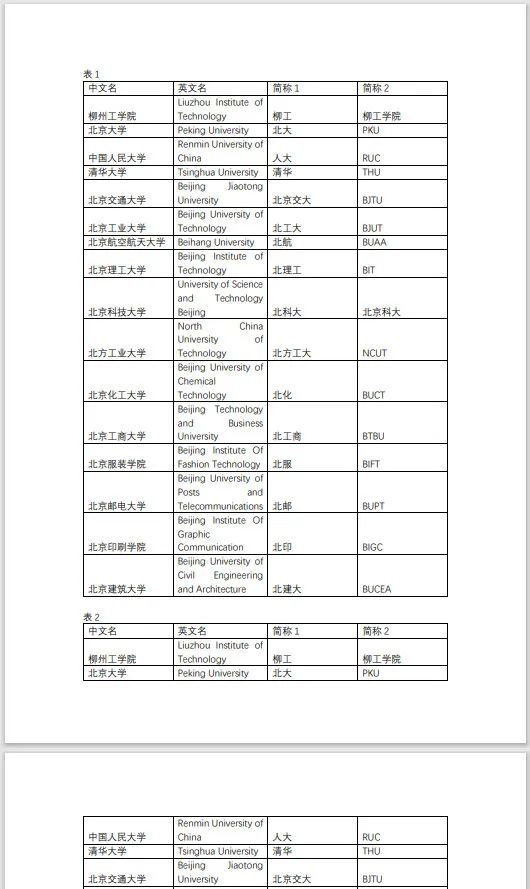
3、pdfplumber提取表格数据 提取表格数据主要用到extract_tables()和extract_table()两种方法,这两种提取方式各有不同。 用以下pdf文档,作为演示文档。
(1)extract_tables()方法 输出文档所有表格,返回一个嵌套列表,其结构层次为table-row-cell。如:
(2)、extact_table()方法 不会返回文档的所有表格,仅返回行数最多的表格数据,如存在多个行数相等的表格,则默认输出顶部表格数据。返回的数据结构层次为row-cell,表格的每一行都为一个单独的列表,列表中的元素即为原表格的各个单元格的数据。如:
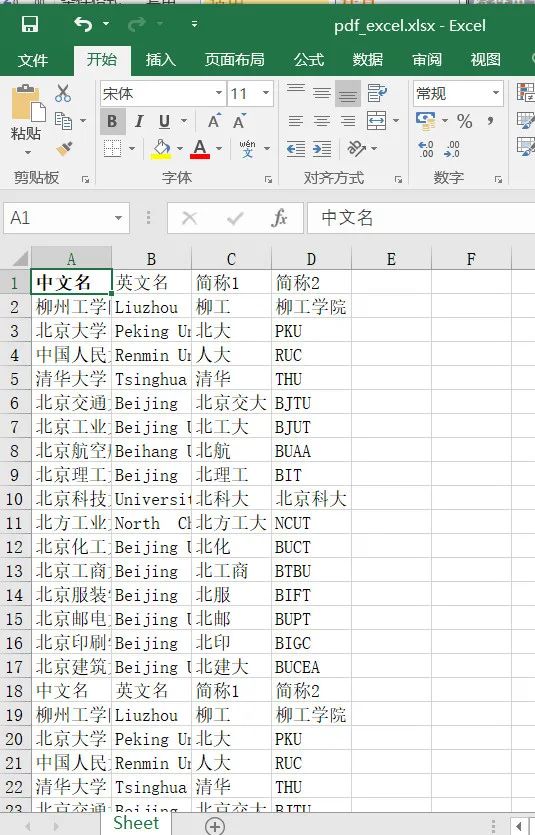
三、提取pdf表格数据并保存到excel中 结合以上方法,综合使用: 提取pdf文件所有表格数据,并保存excel中,部分代码和效果如下: (关注本公众号,回复【pdfexcel】即可获得完整代码,运行并输入文件路径,即可转换成excel)。
以上就是pdfplumber基础知识和表格数据提取方法。 -end- 阅读原文:原文链接 该文章在 2025/8/28 15:44:01 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886