在数字化转型的浪潮,许多管理者常面临一个尴尬的悖论:坐拥昂贵的硬件设备,却在处理百万行级别的 Excel 报表时,被迫面对长达数分钟的「程序未响应」。传闻「Excel 承载不了大数据。」其实并非工具的局限,而在于『法门』的优劣。真正的效率从不与单元格「肉搏」,而是通过内存数组实现对数据的降维打击。
一、 破局:识别效率流失的「隐形黑洞」
为何传统的 VBA 脚本在百万行数据前举步维艰?其核心症结在于三处「黑洞」:
- 频繁的 I/O 交互:每一次 Cells(i, j) 的读写,都涉及 VBA 引擎与 Excel 界面之间跨界通信。
- O(n2)的复杂度陷阱:在百万数据进行嵌套循环搜索,计算量几何级数增长。
- 界面的沉重负累:屏幕重绘与公式自动重算,在海量数据面前成了拖慢航速的锚。
二、 巅峰路径:全内存化一括处理的「三段论」
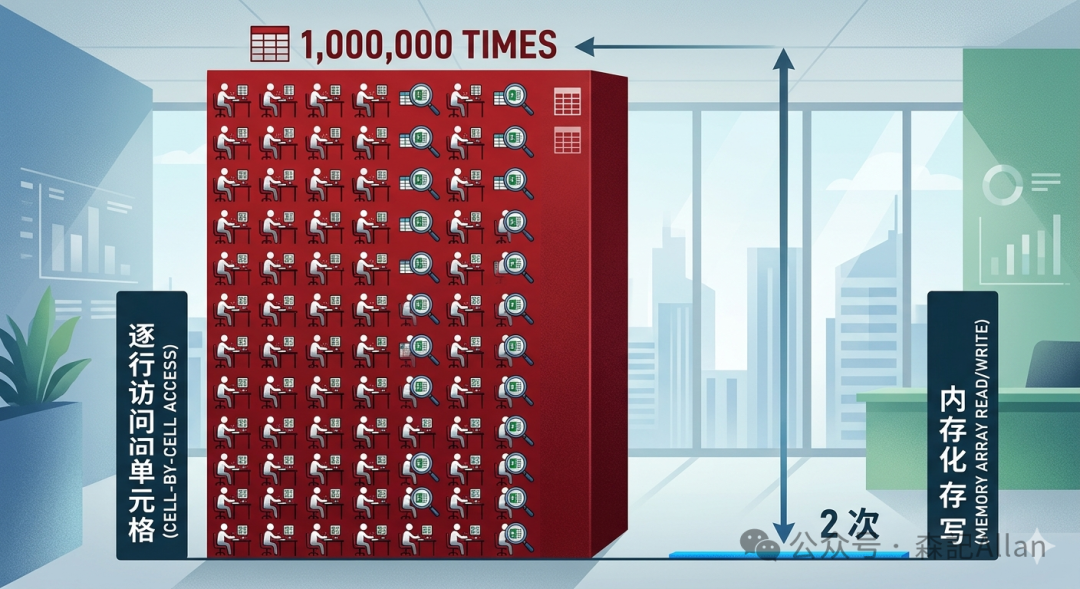
欲「秒级」响应,必先改变 VBA 与单元格之间的频繁通信。核心逻辑:一次将整个工作表读入内存数组,在内存中完成所有计算,最后一次性写回。
1. 瞬间「入库」:全量数据内存化
这是效率飞跃的起点。通过一行赋值,绕过 Excel 复杂的界面渲染,直接读取底层数值。' 关键动作:不再逐行读取,而是「一举吞噬」Dim dataBuffer As VariantdataBuffer = ws.Range("A2:C1000000").Value
2. 内存「暗室」:哈希索引的高速运算
在内存数组用 Dictionary(字典对象)进行哈希索引。所有的比对、累加、条件判断都在 CPU 高速缓存中静默完成。' 关键动作:在内存中利用字典实现 O(1) 查找For i = 1 To UBound(dataBuffer, 1) Dim key As String: key = dataBuffer(i, 2) ' 字典映射:瞬间定位数据位置,无需循环搜索 dict(key) = dict(key) + dataBuffer(i, 3) Next i
3. 定点「投弹」:一键回写结果
计算完成后,严禁逐行输出。必须先在内存中构造好「结果阵列」(Result Array),然后利用 Resize 属性一次性覆盖到工作表。' 关键动作:最后的一记重拳,仅需一次 I/O 交互ws.Range("E2").Resize(dict.Count, 2).Value = resultMatrix
| 维度 | 传统模式 (Cells) | 巅峰路径 (Memory Array) |
|---|
| I/O 交互 | 1,000,000 次(极其昂贵) | 2 次(读 1 次,写 1 次) |
| 搜索算法 | 线性搜索 $O(n^2)$ | 哈希索引 $O(1)$ |
| 界面负载 | 频繁触发重绘与事件 | 零触发(静默处理) |
| 百万行表现 | 约 250 秒 / 软件假死 | 约 3 秒 / 瞬时完成 |
这三行关键代码的组合,实质上是把 Excel 从「电子表格」变成一个单纯的「数据存储器」,而把 VBA 提升为真正的「数据处理器」。
三、 工业级实战代码模板
Sub Performance_Master_V2() Dim startTime As Double: startTime = Timer Dim ws As Worksheet: Set ws = ThisWorkbook.Sheets(1)
' 环境优化:进入「静默模式」 Application.ScreenUpdating = False Application.Calculation = xlCalculationManual Application.EnableEvents = False
' 第一步:入库(一键读取百万行) Dim lastRow As Long: lastRow = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row Dim rawData As Variant: rawData = ws.Range("A2:C" & lastRow).Value
' 第二步:内化(利用字典进行哈希汇总) Dim dict As Object: Set dict = CreateObject("Scripting.Dictionary") Dim i As Long For i = 1 To UBound(rawData, 1) Dim product As String: product = rawData(i, 2) dict(product) = dict(product) + rawData(i, 3) Next i
' 第三步:投弹(构造数组并一次性回写) Dim res() As Variant: ReDim res(1 To dict.Count, 1 To 2) Dim k As Variant, idx As Long: idx = 1 For Each k In dict.Keys res(idx, 1) = k: res(idx, 2) = dict(k): idx = idx + 1 Next k
ws.Range("E2").Resize(dict.Count, 2).Value = res
' 恢复环境 Application.ScreenUpdating = True Application.Calculation = xlCalculationAutomatic Application.EnableEvents = True
MsgBox "处理百万行数据耗时:" & Format(Timer - startTime, "0.00") & " 秒"End Sub
四、 商业启示:效率背后的降维打击
这种「全内存化」的思路,不仅是技术上的精进,更蕴含了深层次的商业逻辑:
- 资源利用率的极致追求: 传统做法是「用人力换结果」,而巅峰路径是「用逻辑调动算力」。当处理耗时从 4 分钟缩短至 3 秒,业务人员的思维连贯性不再被中断,决策效率实现质变。
- 数字化工具的「第二曲线」: 不急于更换昂贵的 ERP 系统,现有工具(如 Excel)巨大潜能有待挖掘。
- 从「操作者」到「架构师」: 掌握内存处理逻辑的职场人,不再是简单的数据搬运工,而是能够在本地端构建「微型数据中心」的架构师。
「博观而约取,厚积而薄发。」 在信息的洪流中,唯有掌握这些「隐形的加速器」,方能先人一步,洞察商业本质。
阅读原文:https://mp.weixin.qq.com/s/CaloprBXidQRf2GeZ4-KvQ
该文章在 2026/4/18 14:56:06 编辑过






 400 186 1886
400 186 1886