节省Token的8种方案
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
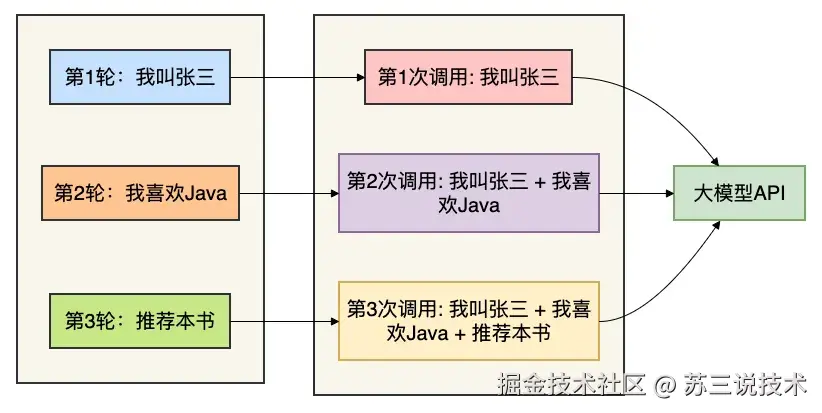
前言最近有球友问:“三哥,我们团队在做AI客服,对话一长token消耗扛不住。有没有一种方案,既能保留完整上下文记忆,又能省token?” 这位朋友的问题,恰恰戳中了当下AI应用开发最头疼的痛点。 既要马儿跑得快,又要马儿不吃草。 这听起来像是矛盾,但经过这两年的摸索,我发现在某些条件下,确实存在“相对两全”的解法。 今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。 更多项目实战在Java突击队网:susan.net.cn 一、为什么记忆必然消耗token?很多小伙伴可能觉得,大模型就像一个人,你说过的话它应该天然记得住。 错! 大模型本质上是一个无状态的函数。 每次调用都是独立的,它没有任何“记忆细胞”。 为了让AI记住之前聊过什么,唯一的办法就是:把历史对话拼接到下一次请求里。 这就是所谓的“上下文注入”。
看到没? 第N次请求携带的历史,是前N-1轮的总和。 token消耗随着对话轮数线性增长——更准确地说,是O(n)级别的增长。 但事情没这么简单。 Transformer模型的核心是自注意力机制,它的计算复杂度是O(n²)。 也就是说,输入长度翻一倍,计算量翻四倍。 更可怕的是,当输入过长时,模型会患上“中间迷失症”——位于长文本中间的信息被严重忽略。 所以,我们的真实困境是:
有没有一条中间道路? 有。 下面我会介绍8种方案,从简单到复杂,从廉价到智能,你可以根据自己的场景按需选择。 二、方案一:全量记忆简单粗暴,但不推荐。 这是最直觉的实现:把所有对话都存下来,每次请求全部带上。 代码解析:逻辑非常直接—— 优点:
缺点:
适用场景:只适合Demo演示、调试测试,或者保证对话不超过10轮的极短场景。 生产环境慎用。 三、方案二:滑动窗口省token,但记性差。 滑动窗口只保留最近N轮对话,超出窗口的直接丢弃。 代码解析: 这样窗口始终保持固定大小。 优点:
缺点:
适用场景:客服快速问答、闲聊机器人、临时对话——那些不需要记住早期信息的场景。 四、方案三:摘要压缩让AI自己总结记忆。 这个方案的想法很巧妙:不保留原始对话,而是定期让大模型把旧对话“压缩”成一段摘要,只保留关键信息。 代码详解:
优点:
缺点:
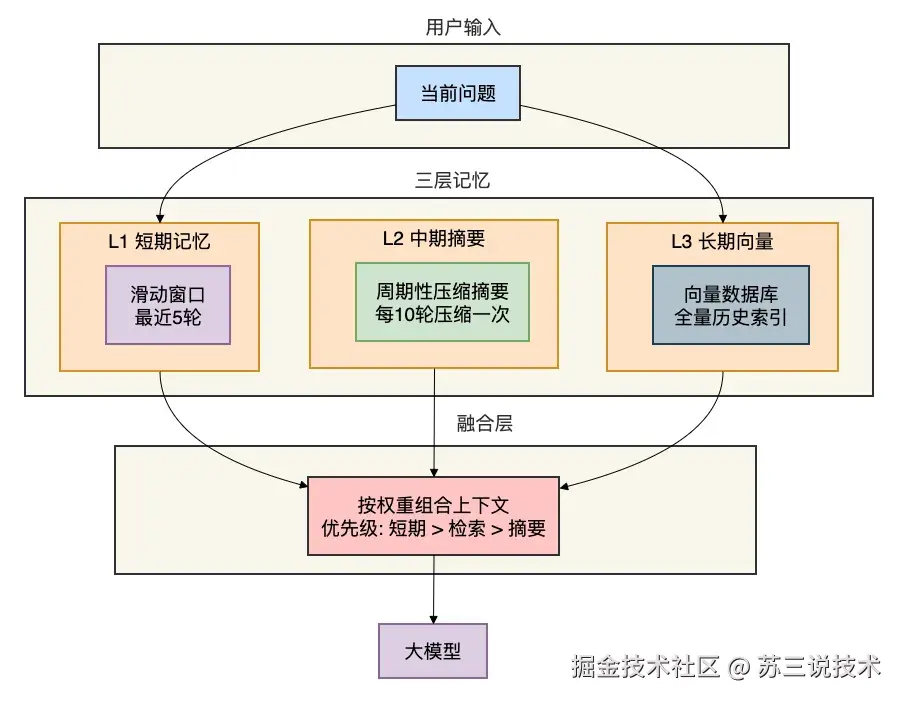
适用场景:长周期对话(几十到几百轮),对信息完整性要求不是100%严谨的场景,比如教育辅导、角色扮演。 五、方案四:向量记忆(RAG)检索相关而不是保留全部。 这是目前工业界最主流的方案。 思路是:不保存全部历史,而是把历史消息向量化后存入数据库,每次只检索最相关的几条历史。 代码详解: 每条消息单独存储,调用 向量数据库存储向量+原始文本+元数据(角色、时间戳等)。 当用户发来新问题时,同样将问题向量化,然后到数据库中做余弦相似度搜索,找到最相似的 这些检索出的历史消息就是“与当前问题最相关的记忆”,拼接进上下文。 优点: token消耗极低:每次只带5-10条最相关的历史,而不是几百条 可以访问非常久远的记忆:只要存储了,就能检索到,不受窗口限制 灵活性高:可以混入知识库、FAQ等外部知识 缺点: 检索可能不准确:如果embedding模型质量差,或者问题与历史的相关性未被捕捉到,就会漏掉关键信息 需要额外组件:向量数据库、embedding服务,增加系统复杂度 有延迟:embedding调用+向量检索,大约增加50-200ms 适用场景:绝大多数生产环境——智能客服、AI助手、个性化推荐等。 这是目前最推荐的方案。 六、方案五:分层混合记忆它是工业级最强方案。 没有单一方案是完美的。真正的工业级系统,往往会组合多种策略,形成分层记忆。 下面这张图展示了一个典型的混合记忆架构:
Java实现的核心骨架 代码解析: L1 短期:滑动窗口保留最近5轮,保证对话连贯性,延迟最低。 L2 中期:摘要压缩,当消息积累到一定程度(比如token超2000或每10轮)就压缩一次,保留全局脉络。 L3 长期:向量数据库存储每条消息,支持按语义检索,解决“长尾记忆”问题。 构建上下文时:优先保证短期(最可靠),然后加上向量检索出的相关历史(弥补窗口丢弃的),最后补充摘要(作为兜底)。 优点: 兼具短时连贯、长时检索、全局摘要,覆盖几乎所有场景 token消耗可控(短期固定+检索topK+摘要) 即使检索失败,摘要和短期窗口也能兜底 缺点: 实现复杂,需要维护多个组件 需要精细调参(窗口大小、摘要频率、检索数量)适用场景:大型生产系统、企业级AI应用,对体验和成本都有高要求的场景。 七、方案六:状态变量提取该方案需要极致的结构化压缩。 有些场景下,真正需要记忆的不是整个对话,而是几个关键状态变量。 比如订票机器人只需要知道: 优点: 极致省token:几KB的状态就能代替几十KB的对话 结构化,模型更容易理解 缺点: 只适合高度结构化的任务(订票、填表、参数收集) 提取状态本身需要调用LLM,有额外成本 适用场景:任务型对话、表单填写、配置向导。 八、方案七:工具/函数调用把记忆“外包”给外部系统。 大模型不是万能的,记忆完全可以交给外部数据库。 模型只需要学会调用“保存记忆”和“查询记忆”的工具。 这种方案让模型自主管理记忆——它觉得重要就存,需要就用。这是目前AI Agent的主流做法。 优点:极其灵活,模型可以按需存取;token消耗几乎为零(只传工具调用结果)。 适用场景:Agent系统、自主决策类应用。 九、终极对比
更多项目实战在Java突击队网:susan.net.cn 总结回到最初的问题:有没有方案既能保留上下文记忆,又能省token? 我的答案是:有,但不存在“免费午餐”。 每一分token的节省,都换来了系统复杂度的增加或记忆精度的下降。 根据我的实战经验,给你几条直接的建议:
该文章在 2026/6/4 11:33:08 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886